How smart is the best AI really? The answer overwhelmingly depends on who you ask. Mostly because some focus on the strengths and others on the weaknesses. In the first school of thought you would get the headline “Pocket Calculator Shown To Have Superhuman Skills”, because it’s true that it surpasses human intelligence on a variety of tasks. In the AI world this is equivalent to the people amazed by AI winning over world chess and go champions. In this sense, AI has been more intelligent than people for quite some time.
But then, as noted in Rebooting AI, if you ask Google, the AI powerhouse, something like “Was Barrack Obama alive in 1994?”, it will give you a link to wikipedia telling you to go figure it out yourself, because it’s too hard for AI to come to this conclusion from the wikipedia by itself (Disclaimer: I work at Google Research, but not on anything mentioned in this post). Yet I’d guess that any chess champion would have no trouble figuring this out after reading the article. So who is smarter after all?
It’s also really important how we will measure the AI intelligence, because the test benchmarks are a huge part of who gets to claim fame in the field, who is deemed to be promising and who gets funding. High quality benchmarks attract high quality progress.
But it’s not like we are sure how exactly to measure people either, so some disagreement is to be expected and one test is unlikely to become the answer once and for all. So far the popular AI benchmarks have been really based each on a rather specific skill, and AI researchers responded to this scheme like when children just practice and practice to be the best at the important test without really learning anything general. Now here is a new proposal to give AI something of a CogAT test. The idea is the same as with children: there shouldn’t be a reason to prepare for the particular test, it’s designed to measure cognitive ability independent of task-specific test prep. Here’s an example question:
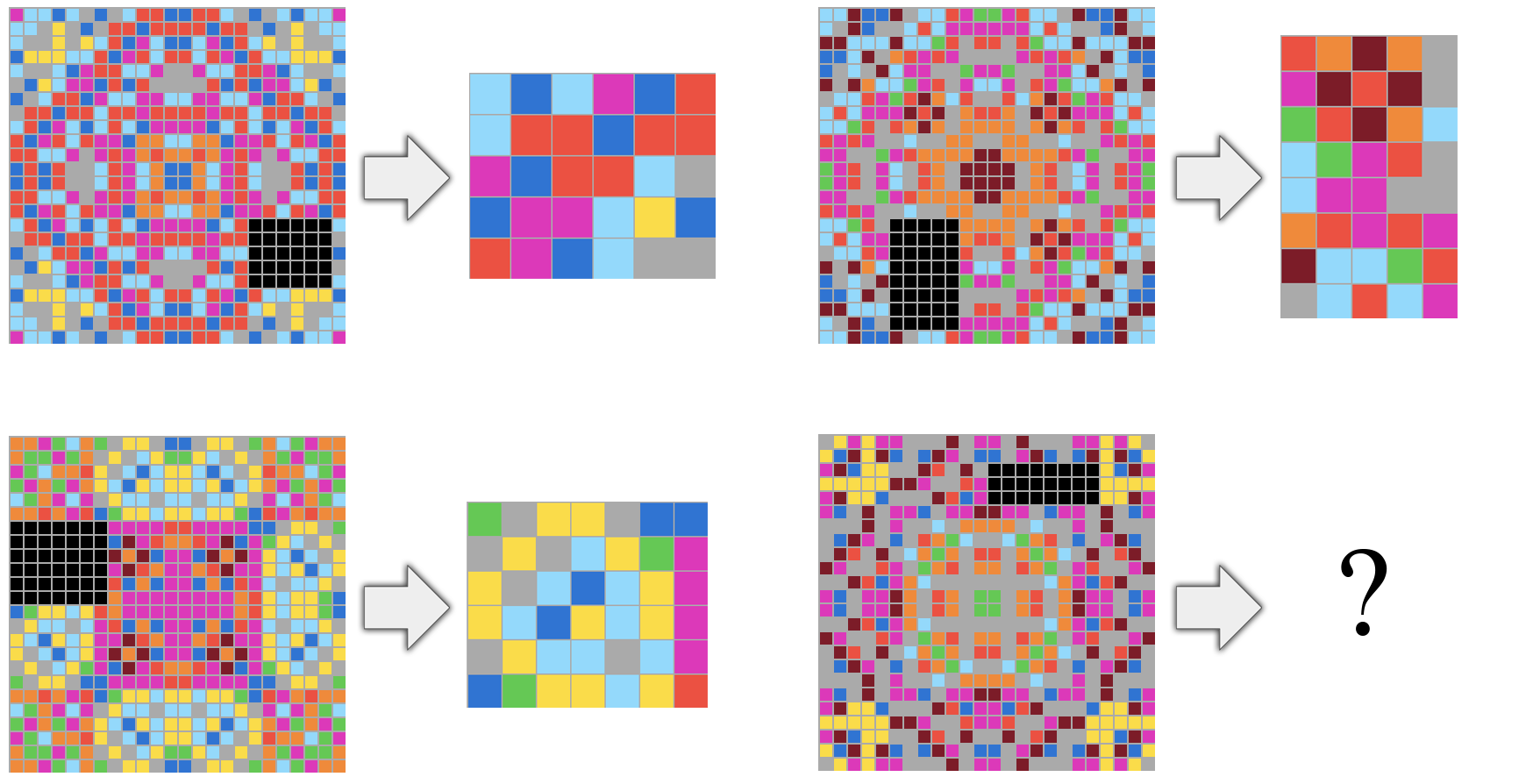
ARC has the following top-level goals:
- Stay close in format to psychometric intelligence tests, so as to be approachable by both humans and machines; in particular it should be solvable by humans without any specific practice or training.
- Focus on measuring developer-aware generalization, rather than task-specific skill, by only featuring novel tasks in the evaluation set.
- Focus on measuring a qualitatively “broad” form of generalization, by featuring highly abstract tasks that must be understood by a test-taker using very few examples.
- Quantitatively control for experience by only providing a fixed amount of training data for each task and only featuring tasks that do not lend themselves well to artificially generating new data.
- Explicitly describe the complete set of priors it assumes, and enable a fair general intelligence comparison between humans and machines by only requiring priors close to innate human prior knowledge.
It’s likely to be a cat and mouse game, just like between CogAT and Testing Mom, but maybe something interesting will come up. It’s scary though that many example problems look like they can be hand-programmed, completely bypassing the need to have any AI to win in this.
Meanwhile there’s another thing: a worker bee would fail miserably on CogAT, yet it’s way more intelligent than current AI, measured by how she can navigate obstacles, find her way around and detect blooming flowers in real time. Why not try to match the skills of these simpler animals first? Maybe AI should first learn to hold the pencil before coming to the CogAT test table. There was a simpler proposal in this direction recently and one thing you can notice immediately, these tasks are much easier for people, yet harder for AI, for example finding mirrors on an image:

It can’t claim it measures the general intelligence, but getting inspiration from our animal evolution could help the AI evolution. After all, really, for an intelligent AI, finding the mirrors on the image shouldn’t be so terribly hard, should it?